I wrote this article (actually more a set of notes than a full fledged article) in order to anchor some concepts out of the “Advanced Distributed System Design” online course, which has been made available for free by Particular Software. I’m not a Particular Software employee nor a user of their products… not even a .NET developer, but the course is very platform agnostic, the trainer shows great mastery and the content is plainly awesome as a for experts refresher or as a primer for beginners.
Fallacies of distributed systems
Network is reliable: it isn’t. So don’t distribute what you can keep together. Strategies for dealing with it, store & forward, retry, transactions, asynch via MQ.
Latency isn’t a problem: latency is a problem. If you scale the latency to a human-meaningful scale, you have that if a read from a registry takes 1 second, a remote call takes some weeks and a reboot can take millenia. So, you should eagerly fetch data, but this creates a trade off with the next fallacy…
Bandwidth isn’t a problem: Bandwidth is the resource that grew the least in the last 20 years. So, relatively speaking, today we have less bandwidth than we had 20 years ago. Bandwidth shortage leads to high latency which in turn can lead to reliability issues (timeout as an effect of high latency, after all). Strategies here are, decompose along business boundaries so that you can assign different priorities to different domains of the relatively scarse resource. In this way you can also limit the “eager fetching” to keep latency at bay.
Network is secure: it isn’t. Even if it were, social engineering can lead to security breaches. A security breach is going to happen: it is not a matter of “if”, it is a matter of “when!”. So you should perform proper threat modelling, trade off risk and cost and involve legal and PR people to mitigate the impact of a data leak.
The network topology won’t change: in a cloud environment, network topology is ever changing. Even out of the cloud, you can’t rely on the topology to be fixed. Using multicast protocols help. Dynamic discovery mechanism help too, but they are hard to implement. Hard coding adresses is a big no-no.
The admin will know what to do: they don’t. You should strive to have backward compatibility, add logs where needed and be ready to have multiple version of your app running.
The transport cost isn’t a problem: remember that remote calls put a huge burden in term of resources (bandwidth, latency, serialization, etc…). If you are in a cloud environment, you pay for every cycle.
The network is homogeneous: at the moment, we are on the verge of an explosion of technologies. Take the cloud: no interoperability here. Standard like REST aren’t really standards.
The system is finished: the dichotomy build/maintain comes from the physical world of building, where very different skills are needed in order to build and maintain a building. In software there’s no such thing: same skills are required to build or maintain a piece of software. Morever, most of the cost of software comes after the go live. So it doesn’t make sense to distinguish maintenance developers from “project” developers. The product approach is a better metaphor.
A good way to communicate an estimate follow this template:
“given well-formed team of x people working only on the task X, there’s %C likelihood that it can be finished between T1 and T2.”
Business logic can and should be centralized: reuse is good but brings coupling, which is not good because it hinders maintainability. However, also not centralizing logic brings maintainability issues in, since you are scattering the logic in multiple places, so you could forget to change something when the need happens. A solution consists in tagging relevant software by feature, so that you can easily remember what is related to a given feature should the change need arise. So long, DRY principle.
A very smart way of tagging consists in leveraging the integration between the VCS (BitBucket), the pull request (BitBucket again) and Jira. If you reference your pull request and commit with the Jira task corresponding to the feature or change being implemented, you can easily see what files were changed to implement the feature.
Maintainability is relevant when things change. Things like business logic tend to change when people actually sta using a system.
Coupling
Coupling is broad term so it often doesn’t have a practical usage. We distinguish Afferent coupling (incoming) from Efferent coupling (outgoing).
There’s no hard rule saying how much coupling is too much. It depends on your architecture. In general, having an high efferent coupling is a “smell” that you may be violating the single responsibility principle. Having an high efferent coupling means that there are a lot of components that could break if I change the module they depend upon. The worst is when you have an high afferent coupling towards a module that i unstable due to high efferent coupling. A module without any coupling is possibly dead code and should be deleted.
There’s no hard, universal, limit on coupling: it depends on your architecture. So you have to define meaningful thresholds for your codebase.
You should treat any violation as something to be peer reviewed: the developer introducing the violation has to explain the reason behind the violation to a peer or remove the violation. By doing so, you limit the number of violation or, at least, share the knowledge of a violation having being introduced. Beware: explain why coupling matter, or developers are going to game the metrics.
Coupling could be difficult to spot. Consider two applications sharing the same database: they are for sure somehow coupled, but no static analysis tool can easily and reliably identify this dependency.
Moving to distributed system, we can define three nuances of coupling:
Platform coupling, also known as interoperability, kicks in when you use proprietary integration protocol such as RMI for Java. Using HTTP (Rest) or other platform-independent protocols prevents platform coupling, but usually you pay some price in term of performance or ease of development.
Avoiding platform coupling requires dealing with two problems: selection of the serialization protocol (binary vs text) and selection of transport protocol (HTTP, SMTP, UDP vs in memory).
Binary serialization protocols tend to be more compact, but harder to get right. Please note that adding “schemas” to a text protocolo (XSD, Json Schema) doesn’t help interoperability: they are meant to increase developer productivity by allowing dynamic remote proxy creation (code generation :)) and automatic validation.
There’s plenty of transport protocols, the most widely used being HTTP. Keep in mind that HTTP could not be the best fit for your use case, e.g., if you have a fire-and-forget, multicast communication, SMTP is a much better fit.
Time coupling happens when computation on a machine A depends on computation on a machine B, typical example being sychronous request-response calls. In a request/response interaction your resources on the clinet are locked until the server process finishes.
A way to avoid that is to move tu a publish/subscibe model, where the former client is the subscriber and the former server is the publisher: the publisher pushes changes to the subscriber instead of having a client polling from the server.
The main challanges of this approach are:
- you should push events and not commands. Events are in the past tense… they can’t be undone.
- if you transmit relevant business informations, you should state the validity of such information.
- you can’t use this approach if you need ACID consistency. In that case, you can’t use request/response either, so you should change your services boundaries to enforce the required level of transactionality.
Spatial coupling is related to deployment. If an application A has the address of a specific application B hardcoded then you have some sort of spatial coupling, since applicarion A breaks if application B address changes.
Messaging
Leveraging asynch technology such as a queueing system reduces temporal and spatial coupling: apart from the message schema and serialization format, publisher and subscriber don’t share anything.
The easiest pattern of asynch messaging is fire and forget. In this pattern, the client sends a message and continues its processing, oblivious of the message processing result on the other side of the queue.
Most of the messaging system internally implement some sort of store and forward mechanism: the message is stored on the client machine by a fast, synchronous call, then the messaging system forwards it to the remote system where the receiving part of the messaging system reads the message and delivers it to the right consumer. Since the remote call can go wrong, the messaging system manages under the hood retry mechanisms, relying on message unique identifiers for correlation and to avoid duplicated deliveries. Some messaging systems automatically set the unique message identifier, some others delegate the task to the sending client.
High availability and foult tolerance are usually managed by mean of clustering techniques. The actual behavior is often configurable, since in may not always make sense to have persistent messages.
From the performance perspective, RPC may have lower latency than queuing for small volumes, but as the volume rises, RPC performances tend to decline while messaging throughtput tends to remain stable.
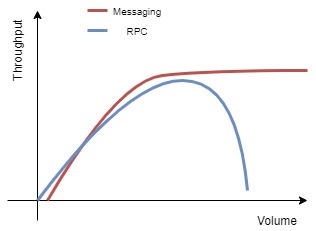
The reason behind this behavior is that blocking calls keep resources allocated for a long period of time (remote calls are slow), so your garbage collector will move a lot of objects to the tenured generation. Garbage collecting the tenured generation is a blocking operation (all thread stop), so the throughput declines. In extreme scenarios, you may incur in out of memory type of problems. Conversely, an asynch mechanism ensures that resources are freed faster. You can always ending filling up your queues, a but that’s easy scaling problem to solve.
A messaging system in much more fault tolerant than a RPC based one. Let’s see what happens when a server crashed during a synchronous, blocking call to an HTTP based service which stores data to a relational database.
If the server crashes, all outstanding transaction to the database are still open, because the database is waiting for the commit/rollback command. Eventually, all transaction will time out, releasing resources, but the default timeout on the database level is in the order of magnitude of minutes: until then, all resources on the database level won’t be release. This can in turn lead to the database becoming unavailable. And in the meantime all data are lost, since the only place where they live is the crashed server memory.
Conversely, a messaging system immediately stores the request. Any sort of retry mechanism can be put in place to prevent data being lost. According to the kind of error happening during execution of messages, different kind of strategies can be applied (retry, spaced retry, poison message management with DLQ, etc…).
Most messaging systems can be accessed via http calls by remote clients, but this doesn’t qualify as a RPC scenario because the only action being executed by the messaging system is a simple and fast storage to the queue.
When an execution involves RPC call, failure management must consider the characteristics of the remote resource. Is the remote service is idempotent, then a request can be safely resubmitted. If it isn’t, the resource may implement a post-and-query pattern, so it could expose an endpoint where the caller may ask if the remote service has already received a specific request.
A rule of thumb, every step of our integration through messaging should deal with only a single resource other than the messaging system.
Messaging patterns
Some business scenario require that message ordering is guaranteed, e.g., for updates. This isn’t inherently related to asynchronous messaging, it can happen as well with RPC calls. The usual way to deal with it is by using entity versions (optimistic lock) that are pushed to the client, which has to provide them back when trying to update. In an asynch, message based environment, this could lead to some specific problems: what if a message is put on a DLQ? if we enforce perfect ordering, any other message coming after the message that has been put into the DLQ will be discarded until the “bad” message is processed. This may be the expected behavior or not, depending on the business process.
The request-response pattern is widely used. A messaging system can support it by using two channels, one for requests and one for responses. The pattern is usually implemented by adding a “replyTo” header to the first message. This header specifies the address of the response channel. The receiver consumes the header and sends the response back to the producer of the first message. A correlation id is used to match the request and response message. This kind of communication allows multiple responses for a single request.
The publish-subscribe pattern is also widely used. To be more precise, the term should be “subscribe-publish”, since the subscription happens before the publishing. In a distributed queuing system, the subscriber sends a subscription message to the publisher specifying the return address. The publisher sends messages to the return address of each subscriber. In that sense, it’s like a request (subscription message)- multiple response (messages from the publisher) pattern. When the subscriber is also a cluster, you can have two behaviors: the publisher can send a copy of each message to every cluster member or send a single message to a single cluster member. In general, the latter approach is preferred, since you should rely on clustering technology to share the information instead of relying on the publisher updating every cluster member.
Side note: according to some research in Code complete, explaining code to someone else is the much more effective in finding bugs than writing unit test.
Architectural Styles: Bus and Broker
An architectural style is not an architecture: is a pattern you can use to build you system, together with many other. A system can use different architectural styles (MVC, pipe & pilter, layer…). Although there’s plenty of documentation describing the most widely used architectural styles, there’s a general lack of insight on how to mix them to create actual systems.
If you compare software architecture to cooking, is like aving the description of every ingredient without a proper cookbook.
The broker style foresees the introduction of a central system, the broker, toward which all existing application should go to fulfill integration needs. This style was born in the mid-80’s in order to address the challenge of integration. Back in those days, the average company didn’t have a central IT. Every department had its own “analyst-programmer” creating software for the department. Eventually. it became evident the need to integrate all those software island. But integrating N applications requires NxN integrations (theoretically). Moreover, the N application may have been written on different platform, with all sort of interoperability problem. The broker was the solution. Typical broker software provided, and still provides, transformation, integration, routing, failover, lot of connectors. Being a central, single point of failure integration software, it required powerful and reliable hardware, which was the item sold at the time (software wasn’t you really had to pay to, it just came as a needed addition to the hardware). Broker were among the first kind of software tobe sold by itself. This lead to all sort of feature bloating, since vendors used the feature completeness as their unique selling proposition.
The problem with this style is that it embodies the “business logic has to be centralized” fallacy. The broker became more and more bloated with business logic. I you add to the mix the fact that most of the broker doesn’t provide decent unit testing or source control, you’ve got a recipe for huge maintainability problems.
The bus architectural style doesn’t have a central piece of software/hardware you can point out to be the real bus. Is mor a matter of having the right protocol and infrastructure that facilitates event based message exchange among distributed parties.
A good example comes from the hardware world: the PCI bus. The PCI bus solved the problem of having a computer made of parts that could or could not be there (floppy disk, hard drive, printer, etc…). Event when the components were actually present, they could have been created by different vendors. In order to have all those component talk to each other, the “plumbing” had to be “dumb”. The bus style mandates dumb pipes and smart endpoints. The bus must have the bare minimum set of functionalities to allow the communication, but has to be robust toward changes in the publisher and subscribers. This is a huge difference with the feature rich broker world. So a bus should not provide features like content based routing, transformation or aggregation, because this would tie the bus to the producer or consumer format. The most important feature a bus style provides is the separation between physical and logical addresses of producers and consumers.
Most of the ESB that came out with the SOA bandwagon aren’t really good examples of the bus architectural style: they are more brokers that hav been rebranded after the broker started having a bad name (thanks, Gartner :-)). There isn’t anything inherently wrong with that, but taking and ESB to solve problems where a bus style would be more suitable, could lead to a poor result.
Both styles are usefull, there’s no absolute good or bad.
SOA
SOA is an architectural style which tenets are encapsulation, clear definition of boundaries, sharing of data types. It stresses the business relevance of a service: a service without business relevance isn’t a service.
A good definition of service comes from IBM:
a service is the technical authority of a business capability.
In that sense, not every web service qualifies as service and there’s no need to be a web service in order to qualify for being a service.
Unfortunately, the architectural style gained some attention in the late 90’s, when there was a general lack of interoperability among vendors (IBM, Microsoft, Oracle, etc…). This lack of interoperability was addressed by the web services technology. The equation web services = service oriented architecture followed shortly after. The architecturale style anyway doesn’t mandate the usage of web services (or any other technology).
In fact, a service can stretch to the front end layer. In that case we talk about UI composition, where every service provides it’s on front end component that is aggregated at the UI level. This approach minimizes the need to share data among services for the sole purpose of showing them on a UI. On the other side, this approach requires multiple calls from the from the client to the back end, which can be not efficient for mobile application due to the high consumption of resources.
There are two more “special type” of services. The “branding service”, provide the visual consistency in case of ui composition. The “IT/Ops services” provide the low level, NFR-based kind of scaffolding to ensure that concern like authorization and authentication is managed.
The most important and difficult part is finding service boundaries. It requires deep knowledge of the business context. In general, data should not cross the boudary of the service they belong to. Conversely, it is safe (and required) to share identifier of entities. An identifier can be seen has an extreme abstraction, it just represent a concept, like an order or a booking, and concepts are relatively stable for a given context. Details on the other end greatly depend on how you model the abstraction, so they shall be kept inside the service boundary to avoid coupling.
Care as to be applied also when sharing IDs: better to share the ID of stable concept with less stable concept then vice versa. This usually lead to “reverse parent-child relationship”, where a usually stable parent entity id is shared with (i.e. copied to) multiple child entities instead of having the parent entity collecting Id of child entities. This approach could lead to some counterintuitive behaviors like creating an order Id at the beginning of a process just in order to have an Id to share with related entities.
There’s no sequence of step to help you find your service boundaries. There are however some advices worth sharing:
- Designing services following the departments (marketing, sales, etc…) is usually a bad idea.
- Processes tend to involve multiple capabilities, so they are not usually good starting points.
- Entities are seldom belonging to a single domain too, so they aren’t a good starting point either.
A good starting point is to identify things that change together, that influence each other and thing that don’t. Things that don’t influence each other, are likely to belong to different services. Services that get identified at this early stage shouldn’t be given a name to avoid bias. Better name them after neutral concepts, like colors or planets.
Domain experts are very important when trying to identify service boundaries.
SAO and Reporting
Reporting usually doesn’t play well with SAO. Data needed for running reports are often times scattered among different services and you don’t want to put them together for the sake of reporting.
When facing a request to implement a report is to dig into the reason behind the report. More often then not, a report is a workaround for an unmet business requirement, a legacy of how a business user executes some business activities, like looking for some patterns in data. If you can reverse engineer the original need, you can come up with better, event driven solution.
For instance, a business user may want a report listing all orders above a given threshold shipped to some specific countries. His goal is to check if shipping to high risk countries are being done. You can better address his concern by including this pattern in your model and alert him as soon as an order matching the criteria enters the system instead of having to wait for the report being executed. In this way you completely remove the need for the report.
Conversely, data scientist usually require a different type of reporting. Thy basically need the data to identify new patterns. They don’t know what they are looking for untile they see it. So this case is usually better addressed by… simply giving them the data. In any case, you want to include stable business concept in your services and data scientist try to figure them out.
CQRS
Command query responsibility segregation is more a design tool than an implementation tool. Before digging into the pattern, let’s start by defining the concept of collaborative domain vs non-collaborative domain.
A non-collaborative domain is characterized by having a large small number of writers and a large number of readers. Conversely, a collaborative domain has both a large number of writers and readers.
Collaborative domain, if the system is not design accordingly, can take down a system when we have high contention on records: the database will block to sequence multiple updates, the connection will fill up and the client will start receiving connection refused (even for operation on items with low level of contention). A solution could be transforming an update into an insert and moving the calculations from the write (command) to the read (query). This can bring in the concept of eventual consistency, allowing the system to be temporarily inconsistent (like having a negative inventory): it’s the price to pay for high performance in high collaborative domains.
Let’s start by talking about the “Q” side of CQRS, i.e. the query model. For collaborative domain, it’s important to understand how much stale your query model can be to still be considered usefull. We can call the Q persistent view model. This model can be used for preliminary validation, even if it isn’t 100% aligned with the master of data. If we do that, a failure when submitting a command can olny happen has a race condition during a colaboration scenario.
In a nutshell, CQRS as an analysis techniques for collaborative domains suggests to separate the write model (command) from the read model (query) in order to acheive greater scalability by using different schemas and data access modes. This usually works well only when paired with a proper service boundaries identification. As any other technique or pattern is not a silver bullet.
Sagas
Saga is a pattern for dealing with long running processes. With long running process, we mean a process that depends on an external trigger to complete (could be a user click or any external event). The actual time the process takes to complete isn’t relevant to our definition.
Since we don’t know when the external event will arrive, the process must have a state to keep track of the step of the process we are in: the process is stateful.
The classic way of dealing with this kind of process is to split it into multiple transaction, adding compensation logic to “rollback” any interim state when needed.
In a message oriented SAO, a saga can be seen has a stateful message handler which manages an execution of a long running process. The saga handler shall not deal with the process business logic, it shall only deal with the process status.
Domain Model
The term comes from the book “Patterns of enterprise application architecture”. It is a pattern meant to solve a problem of layered architecture, where there isn’t a clear place to put business logic. Please note that in the aforementioned book the term “domain model” is used with a different meaning compared to that of the “domain driven design” book.
The domain model borrows the concept of component, which is a software entity exposing properties, methods and events.
A domain model is no silver bullet. It should be used only when you have complicated and ever-changing business rules. If not, simpler patterns may be a better choice.
Domain model should be highly testable. A set of test tending to break every time you change your domain model is a symptom that you might have failed in designing your domain model.
The domain model doesn’t have to be unique. You can have multiple. You can event have different domain object in different tiers.
A domain model can be modeled as a Saga.
Organizational transition to SOA
Usually big bang rewrite don’t work well. You never have enough time and you and up with half backed solutions. A better approach is to incrementally refactor the system.
If you start from a big ball of mud system, you can begin your refactoring journey by adding events. Every time you touch some part of the system for maintenance purposes, just add events. in this way, you create the hooks to start building around the system. In this way you can start building proof of value, since the extra effort of adding events is low.
The next step could be adding subscribers for the events you already introduced in an opportunistic way. In that way you can show the value of working outside the big ball of mud. In this phase, avoid introducing major changes to the legacy system, since you can’t afford the cost of a big “down” here.
If you consistently show value in the first two phases, you can ask for more resources to carve out some responsibilities from the legacy system. This is the phase where the SAO modelling takes place, since you have to think where to put the responsibility you’re removing from the legacy system.
The last step is attack the database. So far we have just been moving code (functionalities) around. Breaking the database in much worse. Data migrations are hard. This is also the phase when a reorg takes place. Until data are assigned to services, a reorg is not possible nor recommended.